 OmniWeaving
OmniWeaving
Towards Unified Video Generation with Free-form Composition and Reasoning
1Zhejiang University · 2Tencent Hunyuan · 3Nanyang Technological University
*Equal Contribution · §Corresponding Authors · †Project Leader
Work done during Kaihang Pan's internship at Tencent Hunyuan.
News
- 📌 Our model and code are under internal compliance review, and are expected to be publicly available very soon (in one week).
- [2026-03-25] We release the OmniWeaving paper on Arxiv.
- [2026-03-25] We release the webpage. Due to the large number of video demos, page loading may take a moment — please allow a few seconds for all videos to fully load.
Abstract
While proprietary systems such as Seedance-2.0 have achieved remarkable success in omni-capable video generation, open-source alternatives significantly lag behind. To bridge this gap, we propose OmniWeaving, an omni-level video generation model featuring powerful multimodal composition and reasoning-informed capabilities. By leveraging a massive-scale pretraining dataset that encompasses diverse compositional and reasoning-augmented scenarios, OmniWeaving learns to temporally bind interleaved text, multi-image, and video inputs while acting as an intelligent agent to infer complex user intentions for sophisticated video creation. Furthermore, we introduce IntelligentVBench, the first comprehensive benchmark designed to rigorously assess next-level intelligent unified video generation. Extensive experiments demonstrate that OmniWeaving achieves SoTA performance among open-source unified models.
Model Architecture
Following the paper, OmniWeaving is built as an integrated MLLM + MMDiT + VAE framework for unified free-form video generation. The MLLM serves as the semantic parser for interleaved text, images, and video inputs, mapping them into a high-level semantic space and forwarding its hidden states through an MLP connector. The VAE acts as the visual tokenizer, compressing visual inputs into low-level latents, while the MMDiT uses these semantic conditions together with latent noise to generate semantically aligned, high-fidelity videos.
On this basis, we further introduce two extra improvements tailored for advanced reasoning and composition.
- (1) Activating Thinking Mode of the MLLM: Direct MLLM encoding of interleaved visual-text inputs often yields semantic ambiguity due to weak intra-correlations and unclear video creation intents. We elevate the MLLM from a passive feature extractor to an active reasoner. By activating the thinking mode to generate intermediate reasoning steps, it autonomously deduces a semantically precise, enhanced prompt. The hidden states of this enhanced prompt are then forwarded alongside the original MLLM features to condition the MMDiT, effectively bridging the cognitive gap between abstract user intent and pixel-level generation.
- (2) Hidden States DeepStacking: Compositional video generation involving multiple subjects or intricate scenes often relies on both low- and high-level semantic representations. Drawing inspiration from the DeepStacking mechanism in Qwen3-VL, we extract hidden states from a broader range of intermediate MLLM layers to capture a rich semantic spectrum spanning from fine-grained details to high-level abstractions. An MLP connector projects these multi-level features into the MMDiT embedding space. These projected features are then directly added to the corresponding hidden states within the first three layers of the MMDiT conditioning branch, effectively injecting multi-granular semantic guidance into the generative process.
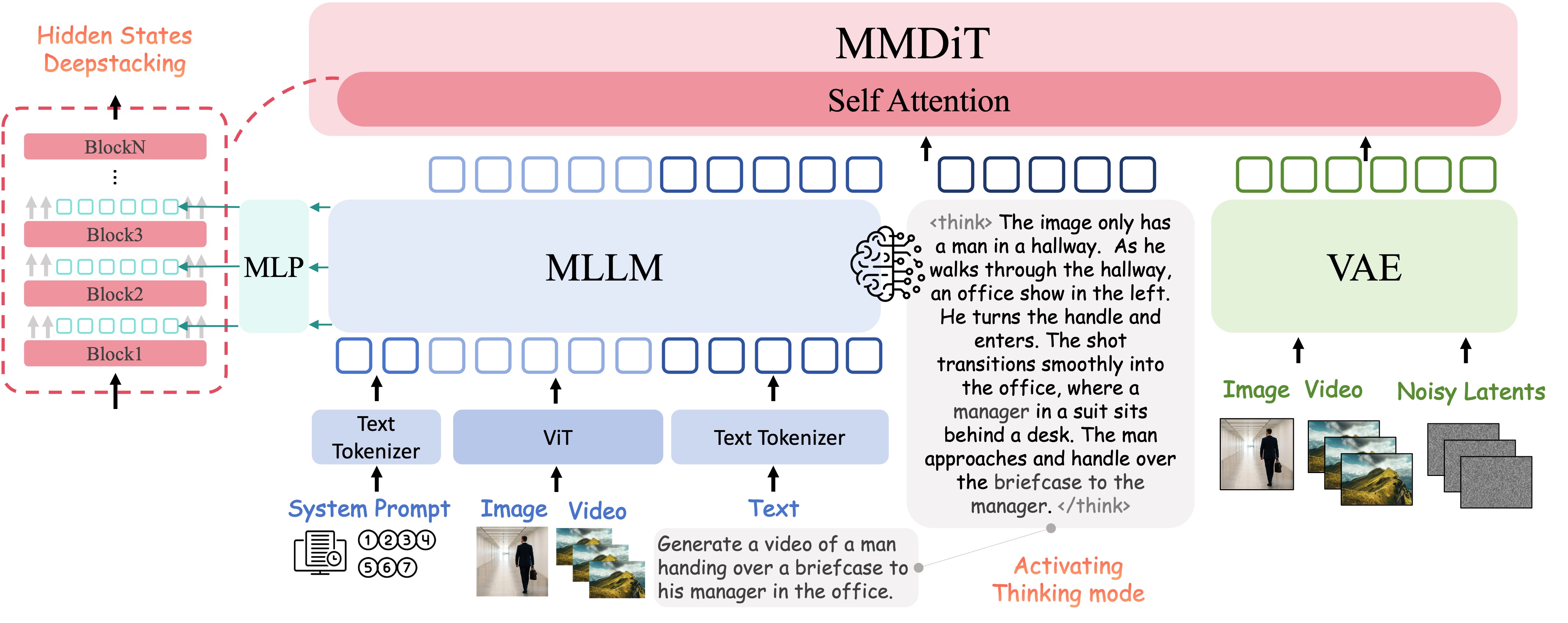
Figure 1. Overview of the OmniWeaving architecture, which consists of an MLLM for multimodal understanding and an MMDiT for generation.
Qualitative Examples
First-Frame-to-Video (I2V)
Image + Text → VideoKey-Frames-to-Video
2 * Images + Text → VideoVideo-to-Video Editing
Video + Text → VideoCompositional Multi-Image-to-Video
1-4 Images + Text → VideoText-Image-Video-to-Video
Video + Image + Text → VideoReasoning-Augmented Video Generation
Image(s) + Text → Reasoning + Video
Input

Prompt: The woman is preparing for an event or outing.
Reasoning
Preparing for an event or outing, the woman confidently checks her appearance in the mirror. Then, she slowly turns her head, her gaze shifting from the mirror to the camera, and finally to the side. Her expression changes from focused to a smile, and she raises her hands to touch her hair, then lowers them.
Input

Prompt: Two girls were reunited with their long-lost dog.
Reasoning
Two girls were happily greeted by their long-lost dog. The girl in the school uniform immediately turns around and kneels down, opening her arms to welcome it. The other girl in the white coat quickly joins. Their expressions transform from initial surprise to pure joy as they pet and finally hug the long-lost poodle tightly, faces pressed together and smiling happily at the camera.
Input


Prompt: Generate a video based on the provided first and last frames.
Reasoning
A child uses a red pump to inflate a basketball, which grows visibly larger as the scene progresses, while another basketball remains deflated nearby.
Input


Prompt: Generate a video based on the provided first and last frames.
Reasoning
Starting with a close-up of the turquoise car's wheel well, the camera smoothly tilts upward, revealing the car’s hood and then the dark grey Volvo station wagon parked on grass in the background, with both license plates visible under soft daylight.
Input


Prompt: Generate a video based on the provided first and last frames.
Reasoning
A gloved hand enters from the left, sprinkling red chili flakes onto the grated cheese topping on the meatballs, enhancing their appearance against the rustic wooden platter and warm wooden table.
Input


Prompt: Generate a video based on the provided first and last frames.
Reasoning
The camera begins focused on a crosswalk where pedestrians are crossing, then smoothly pans right, revealing parked cars lining the sidewalk, and finally settles on a parking sign, capturing the urban street scene.
Main Results on IntelligentVBench
| Type | Model | Params | Implicit I2V (MIN) |
Implicit I2V (AVG) |
Interpolative DI2V (MIN) |
Interpolative DI2V (AVG) |
TIV2V (MIN) |
TIV2V (AVG) |
Compositional MI2V (MIN) |
Compositional MI2V (AVG) |
|---|---|---|---|---|---|---|---|---|---|---|
| Task-Specific | CogVideoX-I2V | 5B | 2.68 | 3.39 | - | - | - | - | - | - |
| Task-Specific | Wan2.1-I2V | 14B | 2.78 | 3.48 | - | - | - | - | - | - |
| Task-Specific | HunyuanVideo-I2V | 13B | 3.00 | 3.80 | - | - | - | - | - | - |
| Task-Specific | HunyuanVideo1.5-I2V | 8.3B | 3.12 | 3.70 | - | - | - | - | - | - |
| Task-Specific | Wan2.2-I2V | 14B | 3.30 | 3.86 | - | - | - | - | - | - |
| Task-Specific | Wan2.1-FLF2V | 14B | - | - | 3.98 | 4.42 | - | - | - | - |
| Task-Specific | SkyReels-A2 | 14B | - | - | - | - | - | - | 2.77 | 3.48 |
| Task-Specific | SkyReels-V3 | 14B | - | - | - | - | - | - | 2.87 | 3.78 |
| Task-Specific | MAGREF | 14B | - | - | - | - | - | - | 2.25 | 3.29 |
| Task-Specific | Phantom | 14B | - | - | - | - | - | - | 2.47 | 3.43 |
| Unified | VACE-Wan2.1 | 14B | 2.76 | 3.40 | 3.32 | 3.86 | 1.27 | 1.53 | 3.17 | 3.98 |
| Unified | VACE-LTX | 2B | 2.20 | 2.87 | 2.59 | 3.10 | 1.20 | 1.35 | 2.07 | 2.48 |
| Unified | VINO | 13B+4B | 2.28 | 3.10 | 1.65 | 2.47 | 2.11 | 2.76 | 3.21 | 3.96 |
| Unified | UniVideo (query) | 13B+7B | 2.77 | 3.39 | 1.76 | 2.48 | 2.66 | 3.46 | 2.74 | 3.57 |
| Unified | UniVideo (hidden) | 13B+7B | 2.95 | 3.61 | 1.84 | 2.58 | 2.56 | 3.36 | 2.91 | 3.74 |
| Unified | OmniWeaving (w/o think) | 8.3B+7B | 3.11 | 3.72 | 3.99 | 4.45 | 3.31 | 3.89 | 3.70 | 4.31 |
| Unified | OmniWeaving (think) | 8.3B+7B | 3.34 | 3.93 | 4.11 | 4.54 | - | - | - | - |
Note: Compositional MI2V MIN/AVG are both computed by weighted aggregation over the three sub-tasks: MI2V = (130 × MI2V-1Subject + 120 × MI2V-2Subjects + 70 × MI2V-3Subjects) / 320, where the weights (130, 120, 70) correspond to the number of test cases in each sub-task.
BibTeX
@misc{pan2026omniweavingunifiedvideogeneration,
title={OmniWeaving: Towards Unified Video Generation with Free-form Composition and Reasoning},
author={Kaihang Pan and Qi Tian and Jianwei Zhang and Weijie Kong and Jiangfeng Xiong and Yanxin Long and Shixue Zhang and Haiyi Qiu and Tan Wang and Zheqi Lv and Yue Wu and Liefeng Bo and Siliang Tang and Zhao Zhong},
year={2026},
eprint={2603.24458},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.24458},
}